Multiple Linear Regression#
Problem#
Given the training dataset \((\mathbf{x}_i,y_i), i= 1,2,..., N\), this time with \(y_i\in \mathbb{R}\) and \(x_i\in\mathbb{R}^{p}\), we fit the multi-variable linear function
Here \(\beta\)’s are regression coefficients, and \(\beta_{0}\) is the intercept.
The data can be written as
Our prediction in matrix form is
Here \(\mathbf{X}\) is a \(N\times (p+1)\) matrix, and is called the data matrix or design matrix.
Training the model#
With the training dataset, define the loss function \(L(\beta)\) of parameters \(\beta\), which is the Residual Sum of Squares (RSS). We could also divide it by \(N\) to get the Mean Squared Error (MSE). This does not change the optimal solution
In matrix form, it can be written as
We arrive at the optimization problem:
To solve the critical points, we have \(\nabla L(\beta)=0\).
In Matrix form, it can be expressed as (left as exercise)
also called the normal equation of linear regression.
The optimal parameter is given by \(\hat{\beta}= (\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}Y\).
The prediction of the model is \(\hat{Y}=\mathbf{X}\hat{\beta}\).
Exercise: Check that when \(p=1\), the solution is equivalent to the single-variable regression.
Evaluating the model#
MSE: The smaller MSE indicates better performance
R-Squared: The larger \(R^{2}\) (closer to 1) indicates better performance. Compared with MSE, R-squared is dimensionless, not dependent on the units of variable.
import numpy as np
from sklearn import linear_model
# A synthetic dataset
N = 100
X = np.random.rand(N,2)
y = 1 + 2*X[:,0] + 3*X[:,1] + np.random.normal(0,0.1,N)
lreg_sklearn = linear_model.LinearRegression()
lreg_sklearn.fit(X,y)
print(lreg_sklearn.intercept_, lreg_sklearn.coef_)
1.0522170865350637 [2.00063258 2.8831766 ]
import matplotlib.pyplot as plt
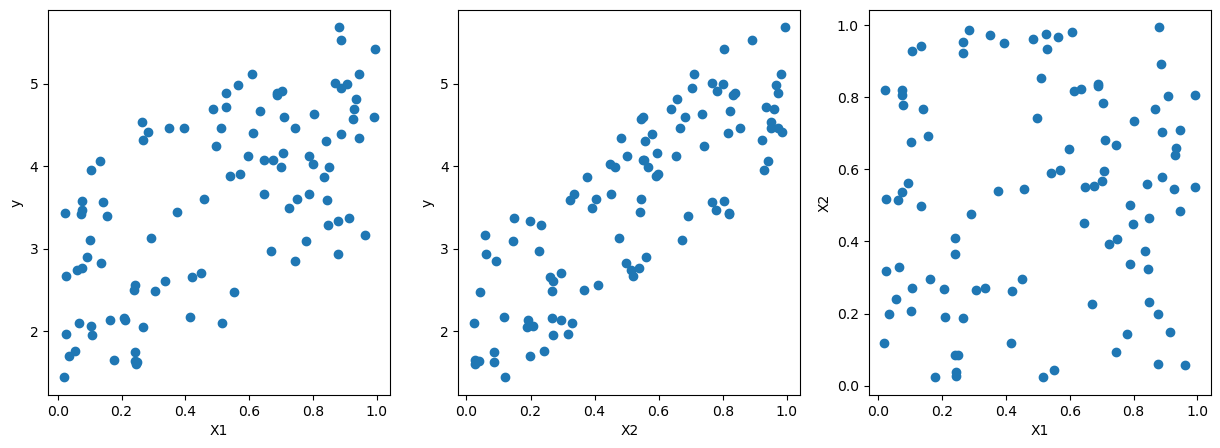
# pairwise scatter plot of X1, X2, y
fig, ax = plt.subplots(1,3,figsize=(15,5))
ax[0].scatter(X[:,0],y)
ax[0].set_xlabel('X1')
ax[0].set_ylabel('y')
ax[1].scatter(X[:,1],y)
ax[1].set_xlabel('X2')
ax[1].set_ylabel('y')
ax[2].scatter(X[:,0],X[:,1])
ax[2].set_xlabel('X1')
ax[2].set_ylabel('X2')
Text(0, 0.5, 'X2')
# solve the linear regression problem using the normal equation
ones = np.ones((N,1))
XX = np.hstack((ones,X)) # add a column of ones to the X matrix
beta = np.linalg.inv(XX.T@XX)@XX.T@y
print(beta)
# the result is the same as the results from sklearn
[1.05221709 2.00063258 2.8831766 ]
# least-squares solution to a linear matrix equation.
beta = np.linalg.lstsq(XX,y)[0]
print(beta)
[1.05221709 2.00063258 2.8831766 ]
/Users/Ray/opt/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:2: FutureWarning: `rcond` parameter will change to the default of machine precision times ``max(M, N)`` where M and N are the input matrix dimensions.
To use the future default and silence this warning we advise to pass `rcond=None`, to keep using the old, explicitly pass `rcond=-1`.
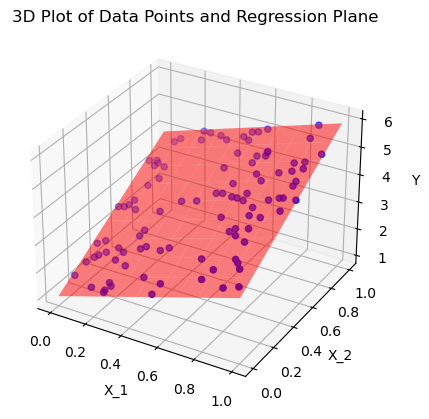
# visualize the data
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# %matplotlib notebook
# Coefficients
coefficients = lreg_sklearn.coef_
intercept = lreg_sklearn.intercept_
# Create the figure and axis
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# Plotting the data points
ax.scatter(X[:, 0], X[:, 1], y, color='b', label='Data Points')
# Create a meshgrid to plot the surface (regression plane)
xx, yy = np.meshgrid(np.linspace(0, 1, 10), np.linspace(0, 1, 10))
zz = coefficients[0] * xx + coefficients[1] * yy + intercept
# Plotting the surface
ax.plot_surface(xx, yy, zz, alpha=0.5, color='r', label='Regression Plane')
# Labels and title
ax.set_xlabel('X_1')
ax.set_ylabel('X_2')
ax.set_zlabel('Y')
ax.set_title('3D Plot of Data Points and Regression Plane')
plt.show()
Using the penguins dataset
import seaborn as sns
df = sns.load_dataset('penguins')
# need to remove missing values
df.dropna(inplace=True,thresh=6)
# predict body mass from flipper length and bill length
lreg_sklearn = linear_model.LinearRegression()
X = df[['bill_depth_mm']]
y = df['body_mass_g']
lreg_sklearn.fit(X,y)
lreg_sklearn.score(X,y)
# use more features
X = df[['flipper_length_mm','bill_length_mm','bill_depth_mm']]
lreg_sklearn.fit(X,y)
lreg_sklearn.score(X,y)
0.7614704841272493
from sklearn.model_selection import train_test_split
# split the data into training and test sets with a 50% split
# set random_state to get the same split every time
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=1)
# fit the model on the training set
lreg_sklearn.fit(X_train,y_train)
# evaluate the model on the training and test sets
train_score = lreg_sklearn.score(X_train,y_train)
test_score = lreg_sklearn.score(X_test,y_test)
print(train_score,test_score)
0.7805532500355294 0.7390137814499202
Colinearity#
If two variables are highly correlated, intuitively, we can say that they are measuring the same thing. In the context of linear regression, this is called multicollinearity.
Suppose \(Y = aX_1\) and \(X_2 = bX_1\), then we can write \(Y = \beta_1 X_1 + \beta_2 X_2\) for any \(\beta_1\) and \(\beta_2\) such that \(\beta_1 + b \beta_2 = a\).
We can see that the coefficients are not unique.
This cause a few problems:
Interpretation: it’s difficult to interpret the coefficients. Originally, we would say that a one unit increase in \(X_1\) would lead to a \(\beta_1\) increase in \(Y\). But now, we can’t say that, because we can’t change \(X_1\) without changing \(X_2\).
Large Variance of the parameter: Since there could be infinite solutions, there is no guarantee which one the solver will find. Therefore small changes in the data could lead to large changes in the coefficients.
Numerical Stability: Sometimes the solver can’t find the solution.
However, this does not affect the prediction: even though the coefficients are not unique, the prediction will be the same.
X = np.random.uniform(0,1,(100,1))
# append collinear columns
X = np.column_stack((X, X[:,0]*2))
y = X[:,0] + np.random.randn(100)
# regression with X0 and X1=2*X0
lreg_sklearn = linear_model.LinearRegression()
lreg_sklearn.fit(X,y)
score = lreg_sklearn.score(X,y)
print(lreg_sklearn.coef_, lreg_sklearn.intercept_,score)
# regression with X0
lreg_sklearn.fit(X[:,0:1],y)
score = lreg_sklearn.score(X[:,0:1],y)
print(lreg_sklearn.coef_, lreg_sklearn.intercept_,score)
[0.19333537 0.38667073] -0.14522663301841937 0.09402953511889811
[0.96667683] -0.14522663301841948 0.09402953511889811
Interpretation of the coefficients#
The coefficient can be interpreted as “the change in the target variable for a one-unit change in the predictor variable, holding other predictors constant”.
Does the size of the coefficient mean “importance”?
This interpretation can make sense in some cases when the variables are of the same scale and “comparable”. For example, if Y is the house price, and X1 is the size of the living room in square feet, X2 is the size of the garage in square feet. Then maybe the coefficient of X1 is larger than X2, and we can say that the size of the living room has more impact on the house price than the size of the garage.
Generally, the size of the coefficient is not a good indicator of the importance of the feature. The size of the coefficient is affected by the scale of the feature. If we change the unit of the feature, the coefficient will change accordingly. For example, if we change the unit of the feature from meters to centimeters, the coefficient will be 100 times larger. However, the importance of the feature does not change.
But we can ask the following question:
If we exclude or include a feature from the model, how much does the model performance decrease or increase?
If the model performance decreases significantly when we exclude a feature, then we can consider the feature to be important in making predictions.
We would like to find the smallest set of features that give good performance. By selecting only a few features, the model is also easier to interpret: For example, for medical diagnosis, we would like to use as few features as possible to make the diagnosis instead of doing all the lab tests available.
Some methods to select the features include:
Best subset selection: Try all possible subsets of features and choose the one that gives the best performance.
Forward selection: Start with an empty set of features. Add the feature that gives the best performance. Continue adding features until the performance plateaus.
Backward selection: Start with all features. Remove the feature that gives the smallest decrease in performance. Continue removing features until removing any feature significantly decreases the performance.
However, for the forward and backward selection, the result might depends on the order of adding/removing features. For example, suppose \(Y = X_1 + X_2\). \(X_3\) is highly correlated with \(X_2\). Then both (\(X_1\), \(X_3\)) and (\(X_1\),\(X_2\)) are good models. If we start with all (\(X_1\), \(X_2\), \(X_3\)), we might end up with (\(X_1\), \(X_2\)) or (\(X_1\), \(X_3\)) depending on the order of considering the features.
How to make use of categorical features?#
In the penguins dataset, the species is a categorical feature. From the pairwise scatter plot, when we color the data points by species, we can see that different species seems to have its own “trend”.
In Homework 4, we consider how to include categorical features in linear regression.